李彦宏表示,DeepSeek并非万能,存在诸多痛点,如幻觉多、速度慢等,尽管DeepSeek在搜索技术方面取得了一定的进展,但仍需要不断完善和改进,针对这些问题,需要持续投入研发力量,加强技术研发和创新,以提高搜索质量和用户体验,也需要保持开放的态度,与其他技术企业合作,共同推动人工智能技术的发展和应用。

电脑知识网报道,4月25日,百度在武汉盛大举行了名为“Create 2025”的百度AI开发者大会,百度创始人李彦宏就“模型的世界,应用的天下”这一主题发表了近一个小时的演讲,他深入探讨了百度在AI领域的最新进展,特别是关于DeepSeek模型的广泛应用及其面临的挑战。
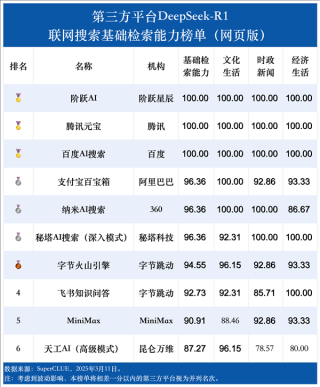
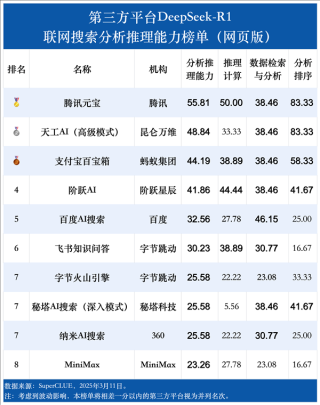
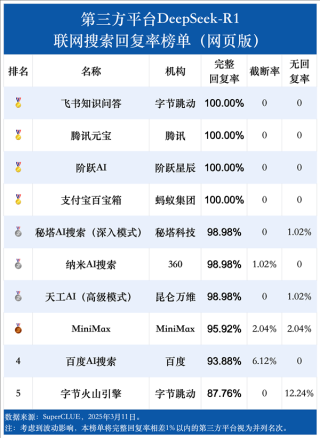
李彦宏首先表示,百度各业务线都在积极接入DeepSeek模型,包括文小言、百度搜索、百度地图等都已接入DeepSeek满血版,并在内外部应用场景中取得了显著的效果,他也强调:“DeepSeek并非万能。”
他指出,虽然DeepSeek在文本处理方面表现出色,但当前只能处理文本,尚不能理解和生成图片、音频、视频等多媒体内容,DeepSeek还存在一些问题,如幻觉率较高,实际应用中有时会出现误判,更大的挑战则在于其处理速度和处理成本,相较于市场上的其他大模型,DeepSeek的速度较慢,成本较高。
为了解决这个问题,百度今天正式发布了文心大模型4.5 Turbo和文心大模型X1 Turbo,这两款新模型主打三大特性:多模态、强推理、低成本,多模态意味着模型能够处理多种媒体类型的数据,包括文本、图片、音频、视频等,这是未来基础模型的标配,相较于纯文本模型,多模态模型的市场需求越来越大。
在成本方面,文心大模型4.5 Turbo和文心大模型X1 Turbo显著降低了大模型的使用门槛,特别是文心大模型4.5 Turbo,每百万token输入价格仅为0.8元,输出价格3.2元,相较于前代产品,速度更快且价格下降80%,而文心大模型X1 Turbo则在性能提升的同时,价格再降50%。
李彦宏强调,降低大模型的成本是AI应用广泛普及的关键,只有当成本降低到企业和开发者都能接受的程度,才能推动各行各业AI应用的爆发,这也是百度不断推出新模型、优化性能、降低成本的重要动力。
此次大会上,百度还展示了DeepSeek和文心大模型在其他领域的应用实例和成果,随着技术的不断进步和模型的持续优化,百度在AI领域的领先地位将更加稳固,期待未来百度能带来更多创新和突破,推动AI技术的普及和应用。
(配图:李彦宏演讲中的DeepSeek模型展示图)